

Tabelle dei caratteri speciali
La sigla "ASCII" sta per: "American Standard Code for Information Interchange", cioè "Standard americano per lo scambio di informazioni". Venne proposto nel 1963 da A.N.S.I (American National Standard Institute) e divenne definitivo nel 1968.
Il codice ASCII fu inventato per le comunicazioni fra telescriventi (infatti ci sono dei codici di comandi specifici che sono quasi incomprensibili oggi ma che al tempo avevano la loro funzione), poi man mano è diventato uno standard mondiale. Si trattava di una codifica a 7 bit che successivamente, per non confonderlo con le estensioni a 8 bit proposte successivamente, venne chiamato US-ASCII. Inizialmente l'ottavo bit, mancante nella tabella US-ASCII, era utilizzato per i controlli di parità finalizzati alla determinazione degli errori di trasmissione.
La tabella ASCII in origine includeva quindi la definizione di 128 caratteri di cui 33 non stampabili definiti solitamente come caratteri di controllo:
| Binary | Dec | Hex | Abbr | C | Description |
|---|---|---|---|---|---|
| 000 0000 | 0 | 00 | NUL | \0 | Null character |
| 000 0001 | 1 | 01 | SOH | Start of Header | |
| 000 0010 | 2 | 02 | STX | Start of Text | |
| 000 0011 | 3 | 03 | ETX | End of Text | |
| 000 0100 | 4 | 04 | EOT | End of Transmission | |
| 000 0101 | 5 | 05 | ENQ | Enquiry | |
| 000 0110 | 6 | 06 | ACK | Acknowledgment | |
| 000 0111 | 7 | 07 | BEL | \a | Bell |
| 000 1000 | 8 | 08 | BS | \b | Backspace |
| 000 1001 | 9 | 09 | HT | \t | Horizontal Tab |
| 000 1010 | 10 | 0A | LF | \n | Line feed |
| 000 1011 | 11 | 0B | VT | \v | Vertical Tab |
| 000 1100 | 12 | 0C | FF | \f | Form feed |
| 000 1101 | 13 | 0D | CR | \r | Carriage return |
| 000 1110 | 14 | 0E | SO | Shift Out | |
| 000 1111 | 15 | 0F | SI | Shift In | |
| 001 0000 | 16 | 10 | DLE | Data Link Escape | |
| 001 0001 | 17 | 11 | DC1 | Device Control 1 (oft. XON) | |
| 001 0010 | 18 | 12 | DC2 | Device Control 2 | |
| 001 0011 | 19 | 13 | DC3 | Device Control 3 (oft. XOFF) | |
| 001 0100 | 20 | 14 | DC4 | Device Control 4 | |
| 001 0101 | 21 | 15 | NAK | Negative Acknowledgement | |
| 001 0110 | 22 | 16 | SYN | Synchronous Idle | |
| 001 0111 | 23 | 17 | ETB | End of Trans. Block | |
| 001 1000 | 24 | 18 | CAN | Cancel | |
| 001 1001 | 25 | 19 | EM | End of Medium | |
| 001 1010 | 26 | 1A | SUB | Substitute | |
| 001 1011 | 27 | 1B | ESC | \e | Escape |
| 001 1100 | 28 | 1C | FS | File Separator | |
| 001 1101 | 29 | 1D | GS | Group Separator | |
| 001 1110 | 30 | 1E | RS | Record Separator | |
| 001 1111 | 31 | 1F | US | Unit Separator | |
| 111 1111 | 127 | 7F | DEL | Delete |
La codifica US-ASCII consente quindi la rappresentazione numerica dei caratteri alfanumerici, simboli di punteggiatura e altri simboli. La rappresentazione mediante codifica numerica è necessaria in quanto il computer può "capire" solo sequenze di bit. Per esempio il carattere "@" è rappresentato dal codice ASCII "64", "Y" dal '"89", "+" dal "43", ecc.
Quando qualcuno richiede delle informazioni in formato ASCII (per esempio il vostro curriculum, oppure un articolo, ecc) significa che richiede un testo salvato in una modalità standard facilmente leggibile da qualsiasi sistema operativo e programma.
Infatti il formato ASCII è universalmente riconosciuto da tutti i computer, cosa non è vera nel caso di testi "formattati", cioè quelli che presentano caratterizzazioni tipografiche come la sottolineature, stili, grassetti, etc. Ecco l'elenco dei caratteri US-ASCII stampabili
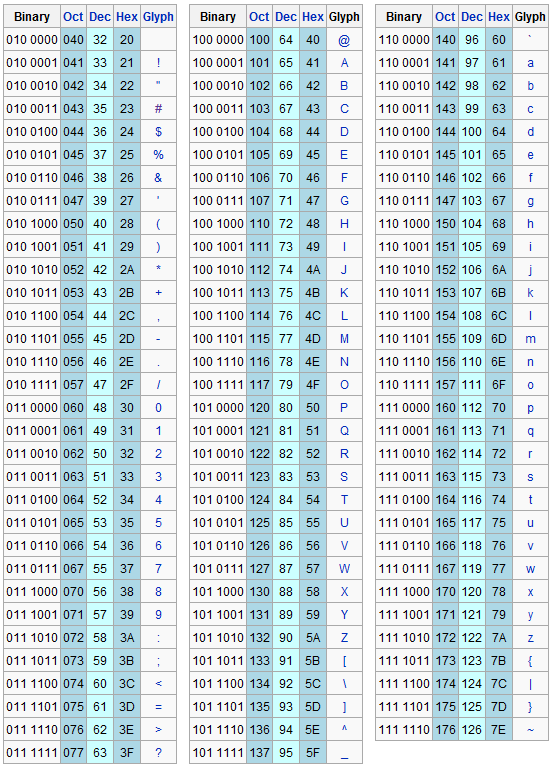
Poiché il numero dei simboli usati nelle lingue naturali è di molto più grande dei caratteri codificabili con US-ASCII è stato necessario espanderne il set di codifica. Le varie estensioni utilizzavano 128 caratteri aggiuntivi codificabili utilizzando l'ottavo bit disponibile in ogni byte.
L'IBM introdusse allora una codifica a 8 bit sui suoi IBM PC con varianti per i diversi paesi. Le codifiche IBM risultavano ASCII-compatibili, poiché i primi 128 caratteri del set mantenevano il valore originario (US-ASCII). Le varie codifiche vennero divise in pagine (code page).
Le diverse code page differivano nei 128 caratteri aggiuntivi codificati utilizzando l'ottavo bit disponibile in ogni byte. I pc costruiti per il Nord America utilizzavano la code page 437, per la Grecia la code page 737, per l'Italia e la Francia la code page 850.
Per vedere in DOS la pagina attiva occorre usare il comando dos chcp.
Ecco il set di caratteri (esclusi quelli US-ASCII) relativi alla code page 850
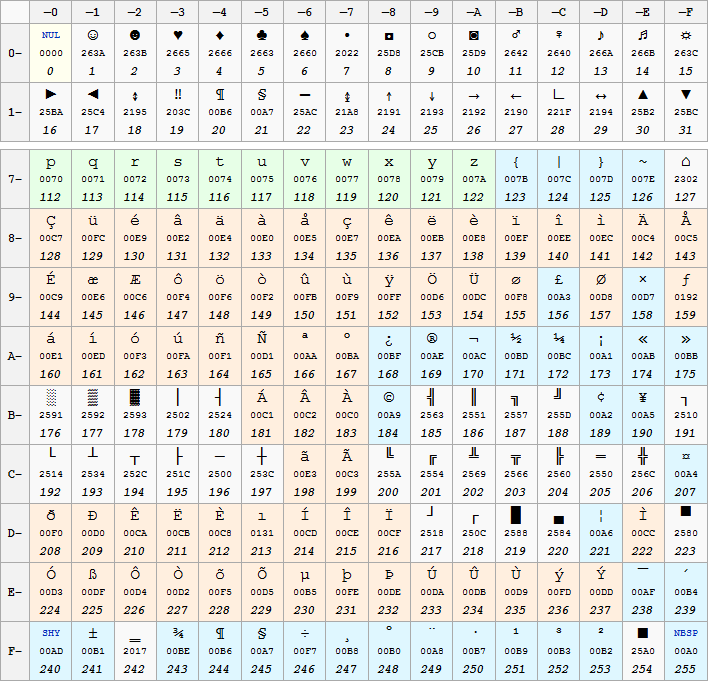
In seguito al proliferare di codifiche proprietarie, l'ISO rilasciò uno standard denominato ISO/IEC 8859 contenente un'estensione a 8 bit del set ASCII. Il più importante fu l'ISO/IEC 8859-1, detto anche Latin1, contenente i caratteri per i linguaggi dell'Europa Occidentale. Tale specifica conteneva per la precisione la codifica di 192 caratteri grafici.
Una particolarità dell'ISO/IEC 8859 rispetto agli altri caratteri estesi è che i caratteri dal 128 al 159, i cui 7 bit più bassi corrispondono ai caratteri di controllo ASCII, non sono usati per non creare problemi di compatibilità.
I codici 00–1F e 7F–9F non sono quindi assegnati ad alcun carattere da parte dell' ISO/IEC 8859-1.
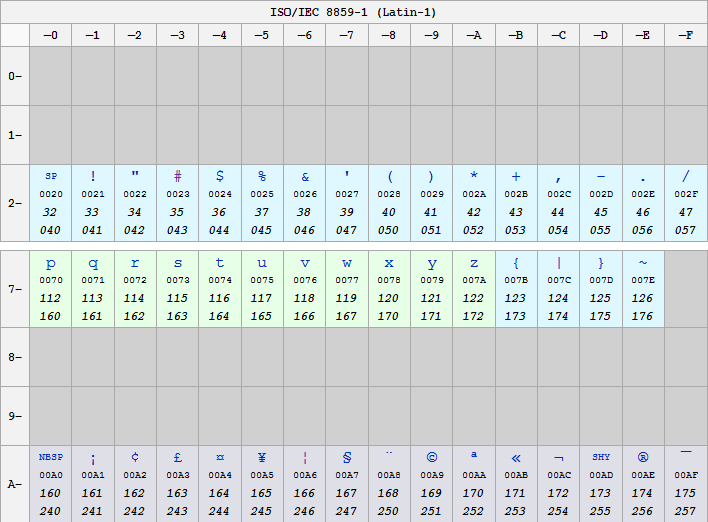
Lo standard ISO/IEC 8859 rappresenta la base di partenza per le codifiche ISO-8859-1 e Windows-1252. Entrambe le codifiche sono un soprainsieme dell' ISO/IEC 8859-1; Aggiungono altri simboli ai 191 caratteri standard.
ISO-8859-1 è la codifica di default dei documenti HTML distribuiti mediante il protocollo HTTP con MIME Type del tipo "text/". Molti browser e clienti di posta interpretano ISO-8859-1 come Windows-1252 in modo da sistemare alcuni errori dovuti alla codifica ma questo non è un comportamento corretto ed è quindi da evitare (da parte di chi sviluppa i browser) .
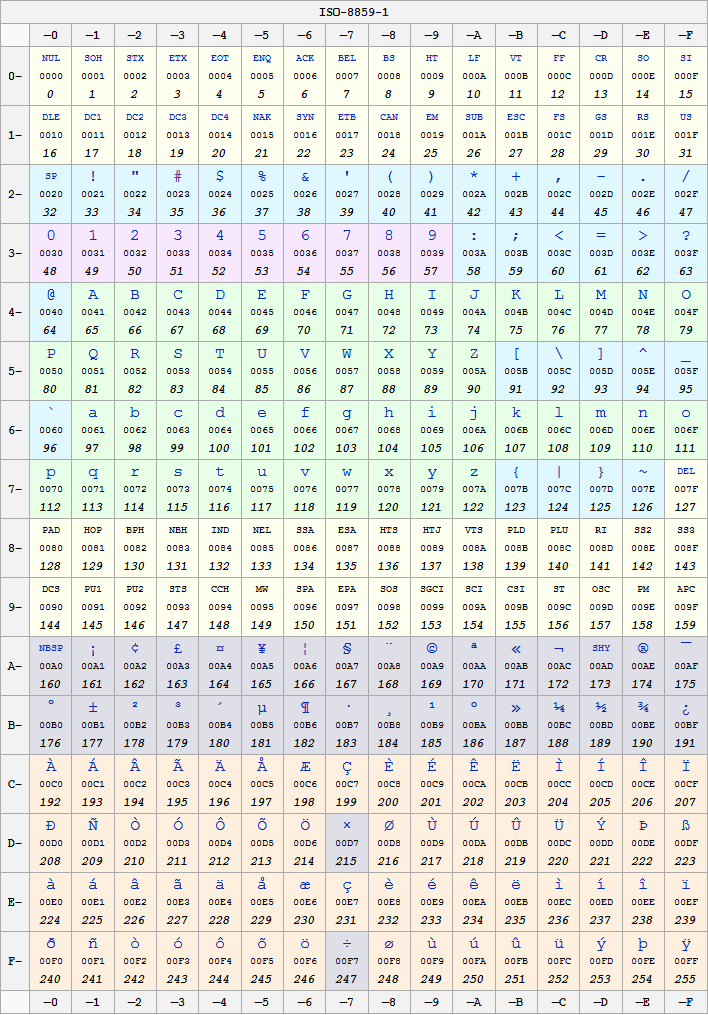
Windows-1252 è stato creato da Microsoft (è un set compatibile con l'ISO 8859-1) ed utilizzato come lo standard di default per le versioni europee di Windows. Windows-1252 coincide con ISO-8859-1 anche per gli intervalli da 0x00 a 0x7F e da 0xA0 a 0xFF, ma non nell'intervallo 0x80 a 0x9F.
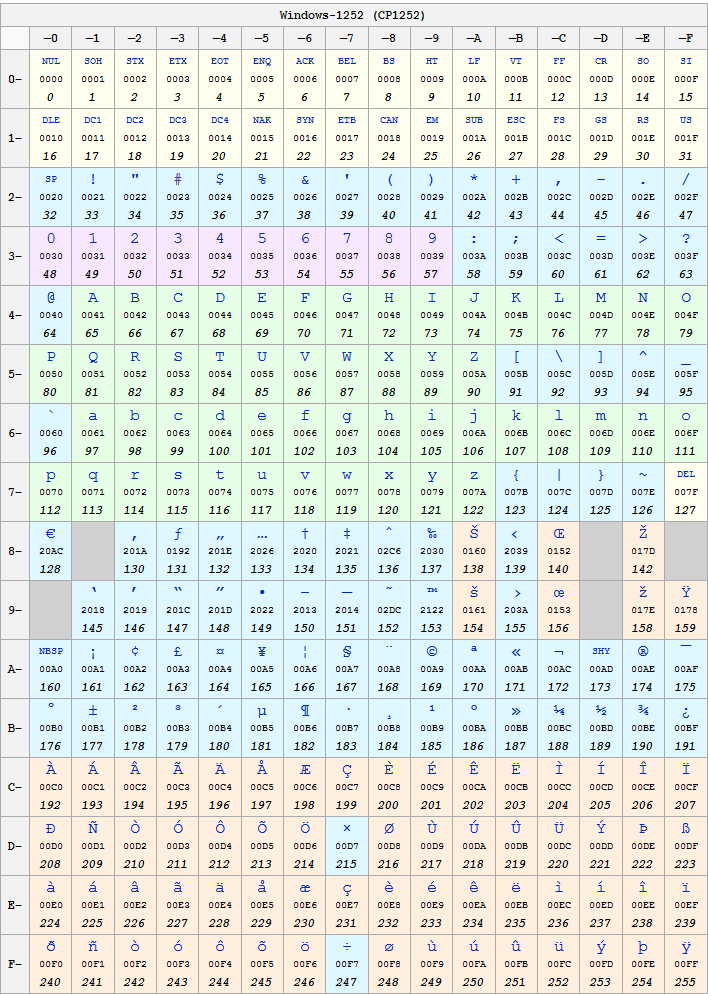
Una nuova codifica chiamata Unicode fu sviluppata nel 1991 per poter codificare più caratteri in modo standard e permettere di utilizzare più set di caratteri estesi (es. greco e cirillico) in un unico documento; questo set di caratteri è oggi largamente diffuso. Inizialmente prevedeva 65.536 caratteri (code points) ed è stato in seguito esteso a 1.114.112 (= 220 + 216) e finora ne sono stati assegnati circa 101.000. I primi 256 code point ricalcano esattamente quelli dell'ISO 8859-1.
La maggior parte dei codici sono usati per codificare lingue come il cinese, il giapponese ed il coreano. L'elenco completo delle tabelle unicode è raggiungibile al seguente link: http://www.unicode.org/charts/



0 Commenti